How to fix unknown crawl errors
Dealing with crawl errors once and for all
This blog post will cover the basics for dealing with crawl errors and how to use URL search tools based on a personal experience I had with crawl errors. The reason why I decided to write this blog post is because last year in August, I was faced with a very sudden increase of the error, “submitted URL has crawl issue”. I saw this error on the “Help” page of the Index Coverage Status Report. Below was the following description:
The submitted URL has a crawl issue:
“An unknown crawl error has occurred that does not apply to any of the above for the URL submitted for indexing. Please use a URL search tool and debug the page.”
The “above” referred to a “Server Error (5XX)” or a “Soft Error (404)”.
An “unknown crawl error” that does not correspond to any of the other classified errors are classified as “unknown”. After being faced with this “unknown crawl error” I didn’t know what to do. How do you go about fixing an “unknown crawl error”? I didn’t know where to begin to solve this mystery. It was then that I tweeted to John Mueller at Google:
“Hello. I have a “Submitted URL has crawl issue” error on GSC. I did “fetch as google” about some URLs with this error, they succeeded to be indexed. These errors depend on a server status at that time, such as request timeout? I’d like to know the possible cause.”
John Mueller responded right away to my question with the following response:
“If you’re seeing crawl errors, and they’re for URLs that you care about, then I’d recommend chasing them down to find the source. Some might be accidental blips on the internet, some might be real issues on your site.”
After getting this response from John Mueller, I had set my mind on chasing down these URLs.
In this post, we will be looking at the specific error, “the submitted URL has a crawl issue” alerted by Search Console (unlike the crawl errors found in the exclusion item section of the coverage report). The exclusion items in the report consist of “crawl errors” including URLs not sent in the sitemap, classified as “unspecified”. It is possible that the response code error is 4XX or 5XX.
The basics of crawl errors and solutions to solve them
Now, while following John Mueller’s advice, the basics of crawl errors can be summed up by the points listed below:
- Crawling errors should be eliminated for efficient and effective crawling
- Determine the order of priority based on the number and frequency of errors and the importance of URLs in error
- Raise caution when a sudden increase in errors has occurred
The larger the website, the more difficult it is to get the crawl error number to 0. In order to do this, first, you need to determine the level of “importance” and “urgency” for the errors. The best way to determine the importance and urgency levels is to look at when the error was detected and where it is happening.
You can download an error sample via a CSV file including up to 1,000 error items from your coverage report. In this report, the URL that detected the error and the crawl date that detected the error are included. The ‘when’ and ‘where’ of the error occurrence can be viewed as a sample checklist, but you can analyze this data as well.
However, it is important to keep in mind that this sample is not a randomly sampled sample as in the sample survey, so it is not strictly a “sample”. Nevertheless, to get a rough idea, it is very useful information.
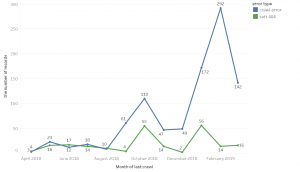
The above graph indicates:
- The submitted URL has a crawl issue (crawl error: blue line)
- The submitted URL has a soft 404 error(soft 404 error: green line)
- The occurrence month is shown on the horizontal axis, and the number of occurrences on the vertical axis while using Tableau to plot the points (data points are samples).
When looking at the graph, you can see that there’s a drastic change with a sudden large volume of blue-colored errors. The green-colored soft 404 errors have waves of change depending on the month, but there is no drastic or sudden change as seen for the blue colored crawl errors. By looking closely at the detection date this way, you can begin to understand the tendency of the error occurrence frequency.
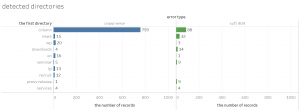
Next, the figure above is a compilation of these errors by location. As explained earlier, the blue indicates crawl errors and the green indicates soft 404 errors. This time, I classified the data by the first directory URL, and tried to illustrate it using Tableau (data is a sample).
By looking at this, you can see that an error has occurred in a specific directory (in this case, the column directory). However, if the number of URLs in the column directory is originally high, it may be natural that the number of errors is high, and it should be kept in mind that it is not a strict sample extraction. Through this method, it is possible to roughly grasp where on the site the problem is occurring by totaling the location where the error occurs.
If you can understand the frequency of occurrence and the trend of the location, you can determine the ‘importance’ and ‘urgency’ of the errors.
For example, if an “important page” on the site has “rapidly” increasing errors it is better to take action as soon as possible. On the other hand, if a “not very important page” has “infrequent” errors, it might not be an urgent problem to look into immediately.
The URL crawl error that I faced was unfortunately found in important directories on the site with a sharp increase. I couldn’t just leave the problem unsolved, so I had to dig and find out what the reason was behind these errors.
Using URL Search Tools
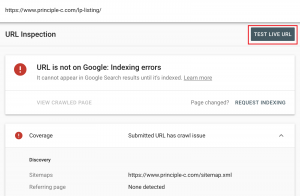
If you have determined which errors to take care of first, given their urgency and importance level, next, you can identify the cause. “Submitted URL has a robots.txt block” “the submitted URL has a noindex tag added” are common crawl error causes that can be immediately recognized and fixed, but an error such as the one I received “submitted URL has a crawl issue” does not explicitly indicate the cause. In this case, you can use a URL search tool and while trying to debug the page, you might find something.
You might have used Fetch as Google as your resource when analyzing your pages, but as shown on this Migrating from old Search Console to new Search Console Page, Fetch as Google is no longer available after March 28, 2019, and it is recommended to use a URL inspection tool instead.
This URL Inspection Tool Page goes into more specific detail on how to use the URL inspection tool; recently, various functions have been added to the tool and it has become quite convenient. When identifying the cause of the error, it is best to try “test public URL”.
If the live test is successful, you can check out the page’s HTML source and screenshots, response code and page release, and other information such as JavaScript console messages from “Display Tested Page”.
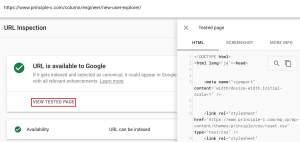
The causes of crawl errors can be so diverse and difficult to identify, but I recommend using the URL inspection tool first.
Unfortunately, in my case, even the URL inspection tool could not help me solve my unknown crawl error. However, by using the URL inspection tool, I was able to identify the cause and find out solutions for “soft 404” errors that occurred at the same time.
Get hints from Google Webmaster Office Hour Hangouts
If you cannot find the cause even after using the URL inspection tool, you can try checking Google US Office Hours Hangout or forums. For example, the Office Hours Hangout on October 19, 2018 answered my question about how to solve the “submitted URL has a crawl issue” error. (https://youtu.be/mDzkW2eX82s ※There is a Q&A session after 30 min). It is mentioned that this unknown crawl error may occur if the number of URLs on the site is high.
You can also check Webmaster Central Forum or the new Webmasters Help Community for any relevant posts for your issue or even post a question yourself. In my case, I found out that it is good to check if there are any signs of crawling on the web server’s raw log, JavaScript rendering timeout, and that the error occurred for my crawl error.
Finally, I was able to look for solutions about my unknown crawl error after examining the raw log and looking for other signs at the time the error was detected. It turns out that Google’s crawlers are frequent when they are concentrated, and while the error was not solved entirely, I was able to know where to start investigating. The journey was long, but I was able to get this far thanks to the specific advice and support from John Mueller and many other people in the community.
Last thoughts
This blog post introduced the basics of how to solve crawl errors and how to use URL search tools. Even though it is challenging to fix all crawl errors, we cannot ignore them. Just as John Mueller advised, it is possible that your crawl errors are signaling real problems going on with your website.
I hope this blog post was able to help you with any “unknown crawl error” issues.
Principle specializes in digital marketing strategy, including web analytics, SEO, product listing ads, Facebook ads, Linkedin Ads and data visualization with Tableau. For more information, please visit our Contact Us page.
Is your Search traffic declining, and don’t know where to start to fix it?
Principle’s SEO audit service is a complete website analysis that will identify your website’s issues. Click here to learn how Principle can unleash your website’s full potential with our SEO audit.

Sr. SEO Consultant
MA from University of Tokyo. After working for the Ministry of Education, Culture, Sports, Science, and Technology for 11 years, Dai worked with an email delivery system and website at an IT venture. Dai is now focused on technical SEO and deployment for growing companies from various industries.